
RINNA社が 5月17日 に、 rinna/japanese-gpt-neox-3.6b-instruction-sft という、対話言語 AI モデルを公開したと、プレスリリースを出した。
その後さらに 5月31日、人間の評価による強化学習したモデル rinna/japanese-gpt-neox-3.6b-instruction-ppo を追加リリースしている。
この AI モデルは、ご家庭にあるミドルレンジ GPU でもサクサク動く性能だったので、 AI 系に明るくない人にも導入できるように、詳しい導入手順を紹介しようと思う。
こう言うのって、登場して直ぐ情報がホットなうちに記事にすることに価値があって、こんな 1~2週間経ってから記事を書いたって誰にも届かないんだろうけど、とりあえず書いてみる。
この界隈の情報はコンテクストが高いというか、あんまりイチから導入方法を説明している記事って目にしないので、多少は需要があるかなと。
はじめに断っておくが、 Chat-GPT や 新しいBing 等と比べると数段落ちる回答精度となる。
ただ、個人がお手軽に購入できる程度の GPU を使って、完全にローカルで動かす事ができるという点が、一種の浪漫だ。
前提条件
以下のスペックを持った PC。
- OS は Windows 10 または Windows 11
- GeForce RTX 3060 以上、 VRAM 12GB 以上が載った NVIDIA の GPU
- GPU ドライバはインストール済み
- 具体的には 2023年5月現在 以下のいずれかモデル
- GeForce RTX 3060 (12 GB)
- GeForce RTX 3080 (12 GB)
- GeForce RTX 3090
- GeForce RTX 3090 Ti
- GeForce RTX 4060 Ti (16 GB)
- GeForce RTX 4070
- GeForce RTX 4070 Ti
- GeForce RTX 4080
- GeForce RTX 4090
- 3070 Ti, 3060 Ti, 3060 (8GB) だと VRAM が足りないので、多分動かすとエラーになる
導入手順
Python のインストール
Python と呼ばれるプログラミング言語(の、「ランタイム」と呼ばれるもの)をインストールする。

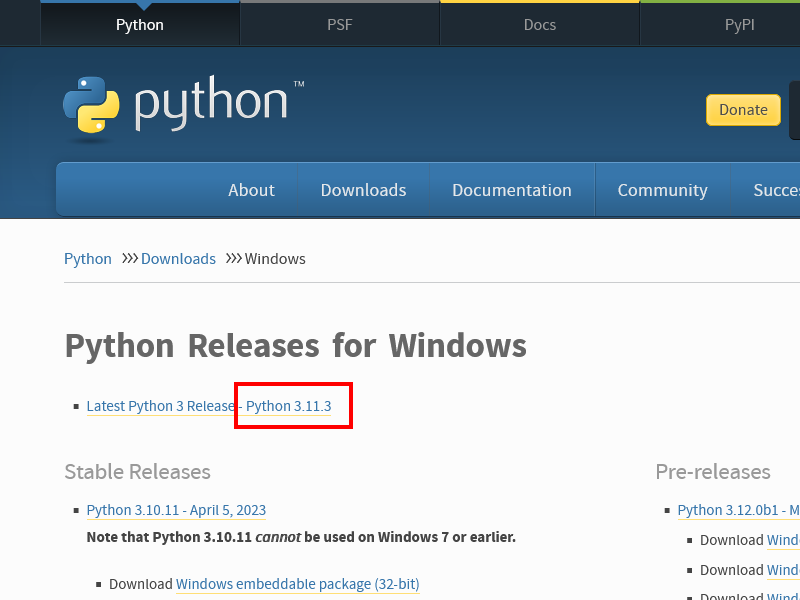
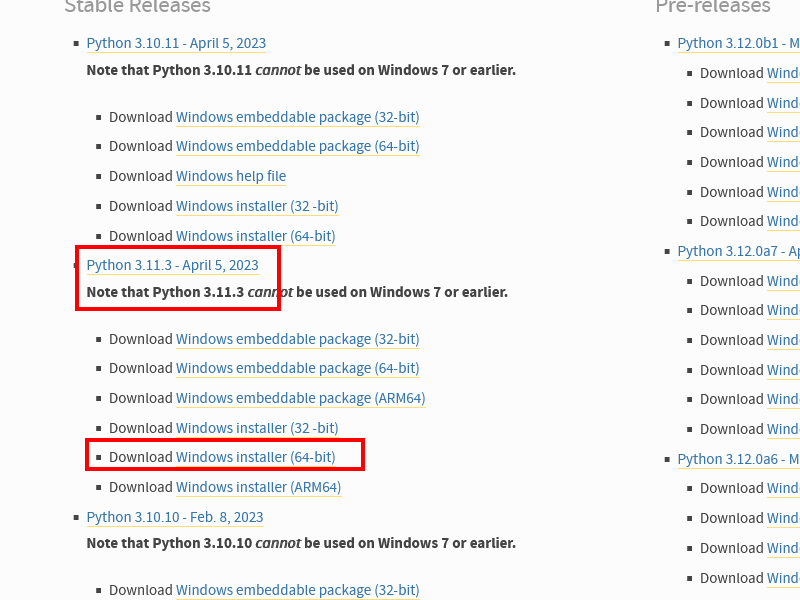
こちらのページから、 Python Releases for Windows の Latest Python 3 Release のバージョン (以下のスクショ だと 3.11.3) を確認し、下のリストからそのバージョンの "Windows Installer (64-bit)" をダウンロード。
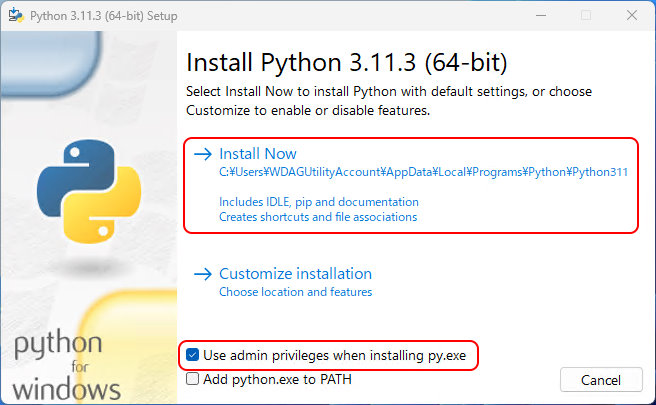
ダウンロードしたインストーラーを実行し、デフォルトの "Use admin privileges when installing py.exe" にチェックが入っていることを確認して、インストールを実行。
Python 仮想環境の作成
先ほどインストールした Python に、追加で必要なツールをダウンロードする環境(仮想環境と呼ばれるもの)を作成する。
まず、これから環境を作成していく元のフォルダをエクスプローラで開き、アドレスバーに powershell と入力する。
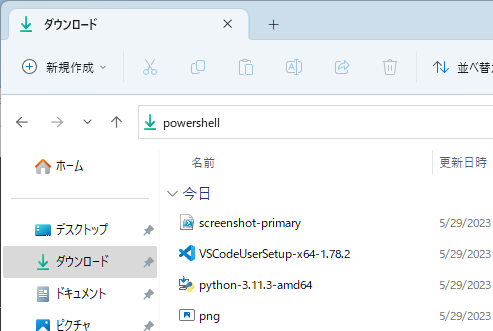
すると、黒い画面が立ち上がるので、以下のコマンドを実行。
py -3 -m venv rinna-japanese-gpt-chatすると、 rinna-japanese-gpt-chat という名前のフォルダ作成されているはず。
vscode のインストール
Visual Studio Code (vscode) という、プログラム用のテキストエディタ(コードエディタ)をインストールする。

Download for Windows からインストーラをダウンロードし実行する。
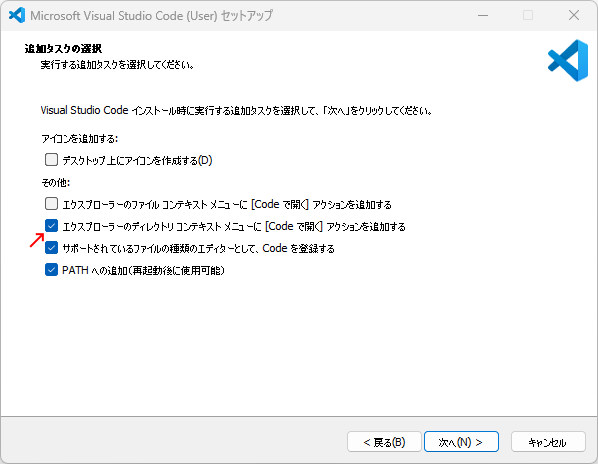
途中、インストールタスクの選択で、「エクスプローラーのディレクトリ コンテキスト メニューに [Code で開く] アクションを追加する」を追加しておく。
スクリプトファイルのダウンロード
実行するスクリプトファイルをダウンロード。
以下のページの右上らへんにある、「Download ZIP」をクリックしてダウンロードした ZIP を解凍し、中にある rinna_gradio_chat.py を、 先ほど作成された rinna-japanese-gpt-chat という名前のフォルダの中に置く。

vscode の環境のセットアップ
後半の作業を簡単にするため、 vscode の環境を整える。
先ほど作成された rinna-japanese-gpt-chat という名前のフォルダを右クリックして(Windows 11 の場合は、更に「その他のオプションを表示を」クリックして)、 「Code で開く」 を選択する。

すると、 vscode が立ち上がる (フォルダを信用しますか?的な Trust 何ちゃらの画面が出たら、 yes を選択しておく)。
Ctrl + Shift + E キーを押すと開く vscode 上の Explorer ペインで、先ほどダウンロードした .py ファイルを選択する。
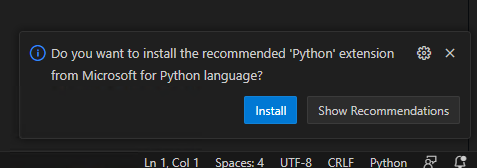
すると、 "Do you want to install the recommented 'Python' Extension..." と聞かれるので、 Install を選択。
インストールが終わったら、再び vscode 上の Explorer ペインで .py ファイルを選択して Ctrl+@ キーを押し、 PowerShell ターミナルを表示させる。

このとき、表示される TERMINAL ウィンドウでは (rinna-japanese-gpt-chat) PS と先頭に表示されるようになっているはずだが、もしそれが表示されない場合は、このターミナル上で .\Scripts\Activate.ps1 と入力しておく。
Python の依存パッケージ (CUDA 対応 CUDA) の確認とインストール
Python で AI を実行するため、 AI 関連ライブラリーを、先ほど作成した Python の仮想環境内にインストールする。
まず、 PyTorch という機械学習ライブラリのページに飛ぶ。

以下のような組み合わせの選択肢を選び、表示されたコマンドを、前述の vscode のターミナル上( (rinna-japanese-gpt-chat) PS と先頭に表示される状態)で実行する。
- PyTorch Build: Stable
- Your OS: Windows
- Package: Pip
- Language: Python
- Compute Platform: CUDA の最新版
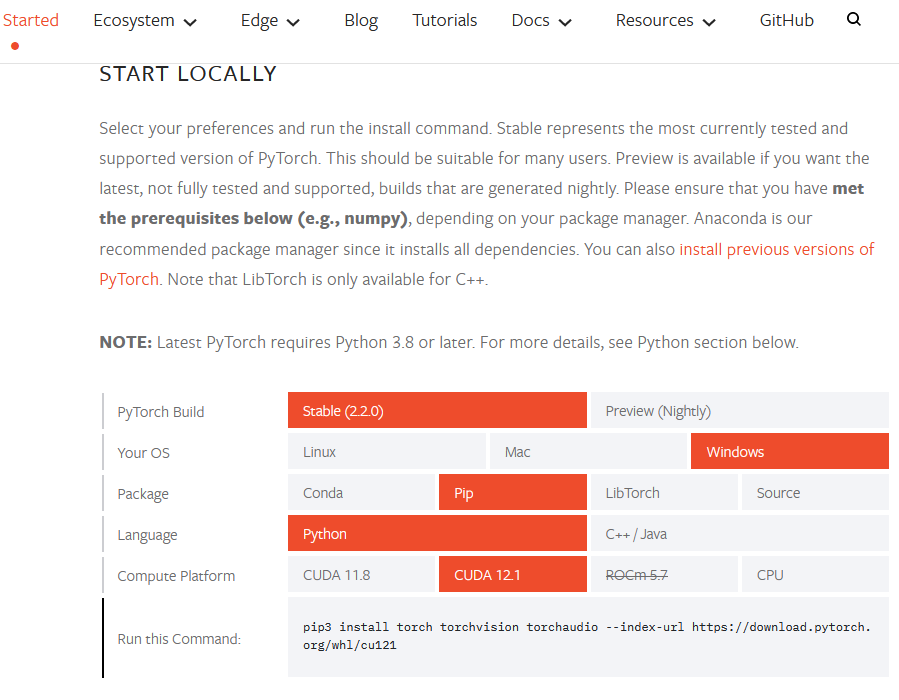
例えば、 CUDA 12.1 の環境をインストールする場合は、以下のようなコマンドになると思われる。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121その後、残りの依存ライブラリもインストールしておく。
pip3 install ipython sentencepiece transformers accelerate gradio
pip3 install の実行順を逆にすると、 CUDA に対応していない torch がインストールされてしまい、後々エラーになってしまうので、必ず PyTorch を先にダウンロードすることが重要だ。
それでも Python コードの呼び出しでエラーとなる場合、ライブラリ更新の互換崩れの可能性がある。
以下のようにバージョンを指定してインストールし直すと、正しく動くかもしれない。
pip3 install ipython sentencepiece==0.1.99 transformers==4.37.2 accelerate==0.26.1 gradio==4.16.0CUDA ツールキットのインストール
最後に、 CUDA と呼ばれる NVIDIA の GPU 上で AI を効率よく実行するためのツールキットをインストールする。
以下の CUDA Toolkit Archive のページを開き、 前項で "Compute Platform" で選択したバージョンの CUDA Toolkit をダウンロードし、インストールする。

最新版ではなく、前項の PyTorch ライブラリのダウンロード時に選択したバージョンの CUDA をダウンロードする必要がある点に注意が必要だ。
例えば、 2024年2月現在、 CUDA Toolkit の最新版は 12.3.2 だが、 前述の PyTorch ライブラリが対応する CUDA が 12.1 までなので、 CUDA Toolkit 12.1.1 をダウンロード&インストールする。
実行手順
vscode のターミナル上( (rinna-japanese-gpt-chat) PS と先頭に表示される状態)で、以下のように実行する。
python .\rinna_gradio_chat.pyしばらくすると、ターミナルにローカルで立ち上がったサーバーの URL http://127.0.0.1:7860 が表示されるので、 Ctrl キーを押しながらクリックして、ブラウザでアクセスする。
あとはお好きなようにいじくり倒すだけだ。
前述の動画は生成部分も含めて等倍速だが、ミドルレンジの GPU でもそれなりの速度で生成できていることがわかる。
停止させたい場合は、ターミナル上で Ctrl + C キーを押そう。
補足
生成速度
ChatGPT などでは元々生成速度が速いので気になりにくいが、 英語と比べて日本語テキストの生成は遅く、同じ情報量で生成時間も利用料金も数倍かかってしまう。
その理由を雑に説明すると、「トークン」と呼ばれる学習・生成の単位が、英語では単語単位となる一方で、日本語は文字単位となっているためだ。
一方、りんなさんこと japanese-gpt-neox-3.6b では、単語間にスペースが存在しない日本語でも、ある程度単語ごとにトークン化されてから処理されるので、生成も文字単位では無く単語単位となり、処理効率が大幅に向上しているのだろうと考えられる。
ChatGPT などが存在しても、国産ないし国内向けの AI モデルが必要とされる理由の一つに、こういった背景があるようだ。
対応GPU
対応GPUを RTX30 世代以降に限っているのは、VRAM の利用を節約するために bfloat16 量子化して動かしているからだ。
この bfloat16 での効率的な計算に対応しているのが Ampere 以降世代の GPU となるためである。
もし、 RTX 10, 20 の GPU で動かしてみたい場合、
https://gist.github.com/advanceboy/717fde162a6f9ccb592f04898f0aacc1#file-rinna_gradio_chat-py-L35
torch_dtype = torch.bfloat16この部分を、搭載 VRAM に応じて torch_dtype = torch.float16 や torch_dtype = torch.float32 に書き換えれば上手く動くかもしれない。
前者の場合、量子化のレンジが狭まるので、応答精度が下がるかもしれない。
後者の場合は、 16~24GB くらいの VRAM が求められるはずだ。
CUI版
わざわざブラウザ立ちあげず CUI 上でチャットしたい場合は、上記のスクリプトの替わりに以下のスクリプトを使うと良いだろう。
rinna_chat_streaming.py
rinna/japanese-gpt-neox-3.6b-instruction-sft を使ったチャット UI のサンプル実装です。 transformers.TextIteratorStreamer API を利用して、 ChatGPT のように生成したテキストを少しずつ表示し、ユーザー体験を向上させています。https://t.co/tXtoN952un— ながいの as a サービス (@longer_n) May 19, 2023
rinna_gradio_chat.pyはいくつかでエラーになります。
修正:
112行目→chatbot = gr.Chatbot(height=500)
115行目→ msg = gr.Textbox(label=”Chat Message Box”, placeholder=”Chat Message Box”, show_label=False, container=False)
130行目→app.queue(max_size=32)
131行目→app.launch(max_threads=2)
gradio 4.12.0
gradio_client 0.8.0
python 3.11.7
遅ればせながら、修正点の指摘をありがとうございます。
gradio v3 から v4 への更新で破壊的変更がありましたね。
コードを gradio 4 用に修正するとともに、 pip で特定のバージョンのライブラリをダウンロードする方法についても、追記しました!