
本記事は、 Microsoft Power Automate Advent Calendar 2023 - シリーズ2 の5日目の記事だ。
"シリーズ1" の4日目は、 @inaho3517 氏の 本でPower Automateを勉強してみた だ。
ちょっとAmazonで検索しただけでも、 めっちゃ本が出てる のね…
知らなかった。
シリーズ2はまだまだ空きがあるので、ぜひご参加を。
実行ステップ数を節約したい
さて、 Power Automate を含め Microsoft Power Platform には、プラン毎に最大要求数の制限がある。
例えば、多くの人が使っているだろう Office 365, Microsoft 365 F3/E3/E5 に含まれる Power Automate の場合、 24時間ごとの 6,000 要求数が上限だ。
Power Automate では、実行されたトリガー・アクションひとつひとつが、結果の成否にかかわらずこの「要求数」を消費する。
大きな数のループや、2重ループなどを行うと、意外と簡単に 6,000 要求数に達してしまう。
時々妥当な範囲で上限を超える程度なら、即時実行をブロックされることはない ものの、設計の段階では超えない事に越したことはない。
唐突だが、アルゴリズムなどの計算量の効率を示す指標として、オーダー表記というものがある。
雑に説明すると、N件のデータを処理するのにどれくらいの勢いで計算コストが増えていくかと言ったもので、例えば単純なループ処理なら O(N), 2重ループとかになると O(N2) といった書き方をするのを、一度は目にしたことがあるのではないだろうか?
ということで、ループによってアクション要求数(ステップ数)が増えがちな Power Automate のコレクションの処理を例に、ループ処理を排除し O(1) の定数時間で処理する方法を紹介する。
とりあえず Office Script?
初っ端からコレを挙げるのは邪道な気がするが、複雑な処理をさせるなら Office Script に投げてしまうのが一番手っ取り早い。
3回/10秒・1,600回/日・120秒/回 の実行制限や、 28.6MiB のパラメータサイズ制限 があるが、どれだけ複雑な処理をさせても 「1回」 しかカウントされないため、 Power Automate の要求数の制限に比べると1日あたりの制限には達しにくい。
JavaScript や TypeScript を書いた経験があるなら、面倒な Power Automate のノーコード作成の UI を色々弄るより、素直に TypeScript 書いた方がよっぽど書きやすいしデバッグしやすいだろう。
ただ、 Office Script は Excel 等の文書に紐づけないと Power Automate から呼び出せず、 Power Automate, Excel Book, Office Script 実体ファイル (*.osts) と複数のファイルにコードが分散するため、チームでの管理がちょっとやりづらい側面がある。
また、 3回/10秒 の制限がなかなかキツく、ループ中に呼び出すことは事実上できないため、コレクションを Office Script に渡すにしても予め Power Automate 側で整形してからの方が良い。
このため以降に説明する、組み込みのアクションと式内関数だけを使った方法が重要だ。
コレクション操作例
まず、 "JSON の解析" という名前で作成した以下のコンテンツを持つ JSON の解析アクション を作成しておく。
[
{
"id": "xx1",
"type": "t1",
"data": [
{ "dtype": "d2", "value": "data1" },
{ "dtype": "d3", "value": "data2" }
]
},
{
"id": "xx2",
"type": "t1",
"data": [
{ "dtype": "d2", "value": "data3" },
{ "dtype": "d2", "value": "data4" }
]
},
{
"id": "xx3",
"type": "t2",
"data": [
{ "dtype": "d3", "value": "data5" }
]
},
{
"id": "xx4",
"type": "t2",
"data": [
{ "dtype": "d2", "value": "data6" }
]
}
]これにより、 body('JSON_の解析') という関数(または、「動的なコンテンツ」に於ける「JSON の解析」の「本文」)でこの内容の JSON が取得できるようになる。
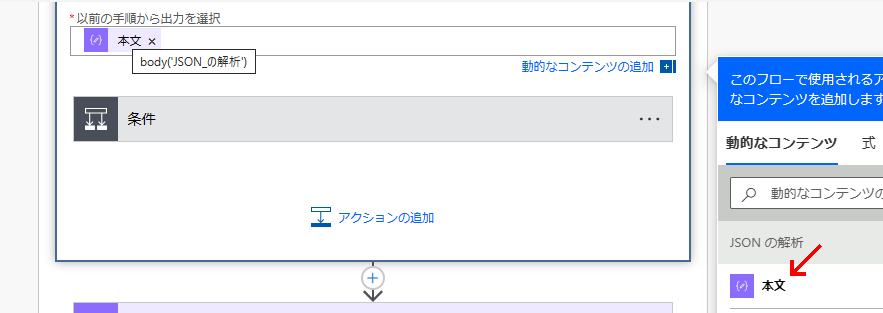
ここで、 type == 't1' でかつ data.dtype == 'd2' となっている data.value の値を抜き出す処理を考える。
JSONPath 的に書けば $[?(@.type=='t1')].data[?(@.dtype=='d2')].value といった処理だ。
期待する結果は以下のようになるはずだ。
[
"data1",
"data3",
"data4"
]素直にループ処理
まずは、素直にループ処理する場合…
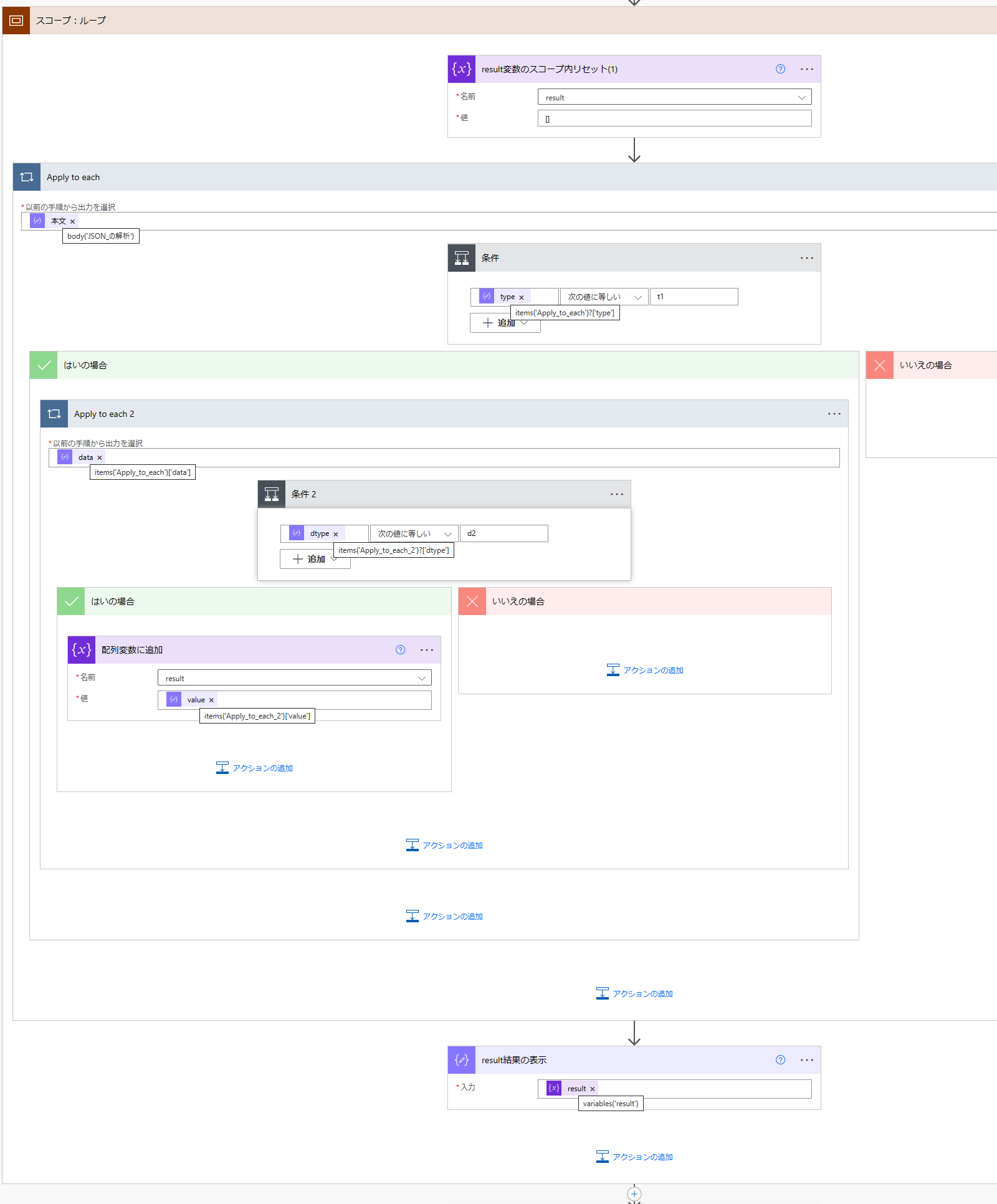
- Array 型の変数(例として「
result変数」を定義)を初期化する "JSON の解析"出力のルート要素 (body('JSON_の解析')) でループする- ループの type フィールド (
items('Apply_to_each')?['type']) が"t1"と一致するなら、dataフィールド (items('Apply_to_each')['data']) で 2重ループする - ループの dtype フィールド (
items('Apply_to_each_2')?['dtype']) が"d2"と一致するなら、 配列変数に追加 アクション を使ってresult変数に value フィールドの値 (items('Apply_to_each_2')['value']) を追加する - 最後に
result変数の値を 作成アクション で出力する
という流れになる。
一応、無駄な2重ループが発生しないように、内側のループは必要な場合のみ回すよう工夫はしているものの、たったこれだけの処理で 13ステップ も消費する。
要素の数が多ければ、 100ステップ などあっという間に到達してしまうだろう。
選択アクションを駆使する場合
一気にややこしくなる。
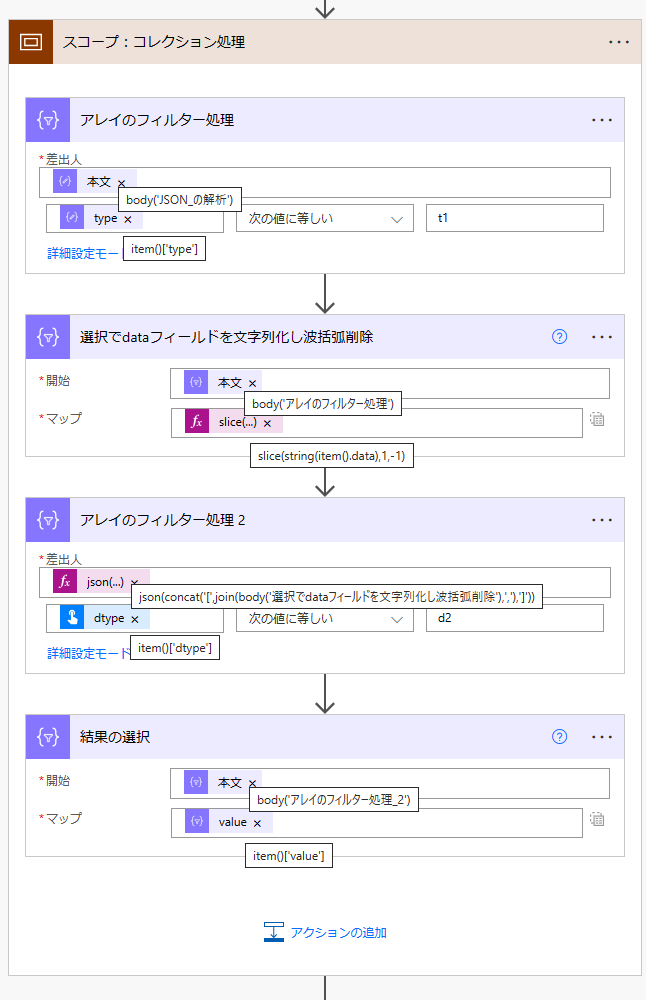
-
「アレイのフィルター処理」 アクション(クエリ アクション) で、
"JSON の解析"出力のルート要素 (body('JSON_の解析')) のうち type フィールド (item()['type']) が"t1"と一致するものをフィルタする。-
コードビュー上は以下のようになる
{ "type": "Query", "inputs": { "from": "@body('JSON_の解析')", "where": "@equals(item()['type'], 't1')" } }
-
-
(1) の出力 (
body('アレイのフィルター処理')) に対して、 選択アクション のテキストモードでdataフィールド (item().data) を射影変換 (JavaScript でいう Array.map(), LINQ でいう Select() の事) する。
このとき、 string 関数で JSON の stringify をし、 slice 関数で両端の[]を取り除く。-
コードビュー上は以下のようになる
{ "type": "Select", "inputs": { "from": "@body('アレイのフィルター処理')", "select": "@slice(string(item().data),1,-1)" } } -
こんな感じの出力となることを想定している
[ "{\"dtype\":\"d2\",\"value\":\"data1\"},{\"dtype\":\"d3\",\"value\":\"data2\"}", "{\"dtype\":\"d2\",\"value\":\"data3\"},{\"dtype\":\"d2\",\"value\":\"data4\"}" ]つまり、
{"dtype":"d2","value":"data1"},{"dtype":"d3","value":"data2"}という文字列と、{"dtype":"d2","value":"data3"},{"dtype":"d2","value":"data4"}という文字列の、長さ2の配列。
-
-
(2) の出力を
','で join して、両端に[]くっつけて、 json 関数 でパースしたものに対して、 「アレイのフィルター処理」 アクション にて dtype フィールド (item()?.dtype) が"d2"と一致するものをフィルタする。-
コードビュー上は以下のようになる
{ "type": "Query", "inputs": { "from": "@json(concat('[',join(body('選択でdataフィールドを文字列化し波括弧削除'),','),']'))", "where": "@equals(item()['dtype'], 'd2')" } } -
つまり、一旦 (2) の文字列配列を以下のような JSON に整形してからフィルタしているといえる。
[ {"dtype":"d2","value":"data1"}, {"dtype":"d3","value":"data2"}, {"dtype":"d2","value":"data3"}, {"dtype":"d2","value":"data4"} ]
-
-
(3) の出力 (
body('アレイのフィルター処理_2')) に対して、 選択アクション のテキストモードでvalueフィールド (item()['value']) を射影変換する。-
コードビュー上は以下のようになる
{ "type": "Select", "inputs": { "from": "@body('アレイのフィルター処理_2')", "select": "@item()['value']" } }
-
この方法だと、要素数がどんな数であっても、必ず 4ステップ で実行できる。
ポイントは (3) の部分だ。
Power Automate のアクションや関数では直接平坦化 (JavaScript でいう Array.flat() の事) ができない。
このため、一度配列を文字列化してから両端の [] を取り除き、 ',' で結合してからまた [] で括って配列としてパースし直している。
このテクニックは、 選択アクション や 「アレイのフィルター処理」 アクション で大量の要素に対して一度に処理する際に色々応用が利くので覚えておくと便利だ。
…まぁ、ものすごく可読性が悪いが。
xpath を駆使する
Power Automate では、 JSON Pointer (RFC 6901) や JSONPath といった JSON の要素選択構文は用意されていないのに、 XML の XPath については何故か xpath 関数 が用意されている。
xml 関数 を使って JSON を XML に変換し、 XPath でフィルタしてやれば、 だいぶ複雑な要素選択もたった1ステップで処理できる。
但し、 XML に変換できる JSON にはいくつか制限がある。
- ルート要素は単一プロパティのオブジェクトである
- 2階層目は配列ではなくオブジェクトである
つまり、以下の様な JSON は変換できる。
| JSON | XML |
|---|---|
|
|
|
|
|
|
しかし、条件を満たさない以下のような JSON は、 InvalidTemplate エラーが発生してしまう。
-
{ "firstName": "Bill", "lastName": "Gates" } -
{ "root": [ "Bill Gates", "Satya Nadella" ] }
また、 XML の仕様上 1要素の配列が表現できないことも要注意だ。
(xpath でフィルタする上ではあまり困ることはないが)
| JSON | XML |
|---|---|
|
|
上記を念頭に置くと、二段構えのJSONオブジェクト {"root":{"item": <JSONの中身> }} で括ってから、 xml 関数 で XML に変換すれば良さそうだ。
具体的な実装は以下のようになる。

-
作成アクション の入力に、以下のような式を指定する
xpath(xml(json(concat('{"root":{"item":',string(body('JSON_の解析')),'}}'))),'/root/item[type="t1"]/data[dtype="d2"]/value/text()')- コードビュー上は以下のようになる
{ "type": "Compose", "inputs": "@xpath(xml(json(concat('{\"root\":{\"item\":',string(body('JSON_の解析')),'}}'))),'/root/item[type=\"t1\"]/data[dtype=\"d2\"]/value/text()')" }
たった 1ステップながら、同じ結果を得ることができた。
XPath の補足
なお、 xpath 関数 で使えるクエリは悪名高い .NET の System.Xml.XPath 名前空間のものなので、 XPath 3.1 はおろか、 XPath 2.0 すらもサポートしていない。
つまり、 ends-with や matches といった XPath 2.0 以降で追加された関数は使えない。
…matches が使えれば、Power Automate で正規表現を使うハックができたのに…
一方で、 XPath 1.0 の範囲なら割と複雑な出力にも対応しており、前述のような text() によるテキストノード以外にも、 XML 要素そのものの選択もできる。
例えば、
<root>
<item>
<type>t3</type>
<data>
<dtype>d2</dtype>
<value>data1</value>
</data>
<data>
<dtype>d993</dtype>
<value>data2</value>
</data>
</item>
<item>
<type>t4</type>
<data>
<dtype>k02</dtype>
<value>data3</value>
</data>
<data>
<dtype>k03</dtype>
<value>data4</value>
</data>
<data>
<dtype>k04</dtype>
<value>data5</value>
</data>
</item>
</root>といった XML 文字列を xmlString 変数に定義していたとして、以下のように複数の XML 要素の戻り値を期待した実行を行う。

-
- 開始 1:
xpath(xml(variables('xmlString')), '//data[number(substring(dtype,2)) mod 10 = number(substring(../type,2)) mod 10]')- マップ:
json(item())
すると、以下のような出力が得られる。
[
{
"data": {
"dtype": "d993",
"value": "data2"
}
},
{
"data": {
"dtype": "k04",
"value": "data5"
}
}
]何故 選択アクション を使っているかというと、テキストノードではなく XML 要素を選択した場合の xpath 関数の直接の戻り値は、以下のような構造になっていてそのままでは扱いづらいからだ。
これらの $content フィールドには、 base64 でエンコードされた XML 要素のシリアライズ文字列が入っている。
[
{
"$content-type": "application/xml;charset=utf-8",
"$content": "PGRhdGE+DQogIDxkdHlwZT5kOTkzPC9kdHlwZT4NCiAgPHZhbHVlPmRhdGEyPC92YWx1ZT4NCjwvZGF0YT4="
},
{
"$content-type": "application/xml;charset=utf-8",
"$content": "PGRhdGE+DQogIDxkdHlwZT5rMDQ8L2R0eXBlPg0KICA8dmFsdWU+ZGF0YTU8L3ZhbHVlPg0KPC9kYXRhPg=="
}
]この戻り値配列をそのまま json 関数 に渡しても、以下のようなエラーになってしまう。
InvalidTemplateです。Unable to process template language expressions in action '作成' 入力の行 '0' と列 '0': 'テンプレート言語関数 'json' は、パラメーターが文字列または XML であることを想定しています。指定された値は 'Array' 型です。使用方法については、https://aka.ms/logicexpressions#json を参照してください。
一方、選択アクション を使って戻り値配列の各要素毎に json 関数 に渡すと、 $content-type を読んで XML として認識した構造を JSON 型のオブジェクトに変換してくれるため、先の出力例のように以降の処理で取り扱いやすい出力が得られるのだ。
参考リンク
Power Automate は Azure Logic Apps がベースになっているため、ドキュメントがあれこれ散ってて調べにくいが、おおむね以下のリンク先を見れば良いはずだ。
ただ、アクション名の日本語訳が UI 上とドキュメント上で全然異なるものが多いため、コードビューから "type" フィールドの名前を調べてそれをキーにして検索した方が良い。翻訳がブレブレなのはホントやめてほしい…
- 組み込みのトリガーとアクションの一覧: (Azure Logic Apps でのトリガーとアクションの種類のスキーマ リファレンス ガイド - Azure Logic Apps | Microsoft Learn)
- トリガーの種類の一覧
- アクションの種類の一覧
- 但し、 JavaScript コードの実行アクション は Power Automate から使えない
- 式で使える関数の一覧:
- 式で使えるオペレーターの一覧:
- 変数コネクタの処理の一覧:
- 標準・プレミアムコネクタのトリガーとアクションの一覧:
-
XPathクエリの動作の説明を補足をしておくと、各
/root/item/data要素について、./dtypeの先頭文字を除いた1の位と、相対位置の../typeの先頭文字を除いた1の位が一致する要素を抜き出している ↩
ピンバック: Power Automate で key-value Array ⇔ Object (Dictionary) を相互変換して Office Script の呼び出しを節約する | Aqua Ware つぶやきブログ